Chapter 2
Listen to what one says and look at what one does. --Confucian
The recommendation system based on user behavior only usually called collaborative filtering. This book mainly introduced three algorithms, neighborhood-based, latent factor model, and random walk on graph.
Before this, we need to know these definitions.
Neighborhood-based
Here are two primary neighborhood-based algorithms, named UserCF and ItemCF.
UserCF
This algorithm consists of two steps:
- Find the set of users whose interest is similar to the target user’s
- Find the item that the users in the set favorite while the target user has not heard of, and then recommand it to the target user.
The first step is to calculate the similarity of users’ interest w. We consider that two similar users have similar item set that they has a positive feedback.
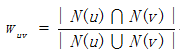
or
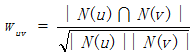
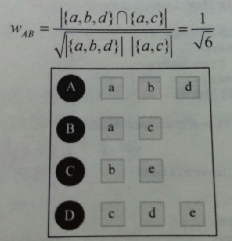
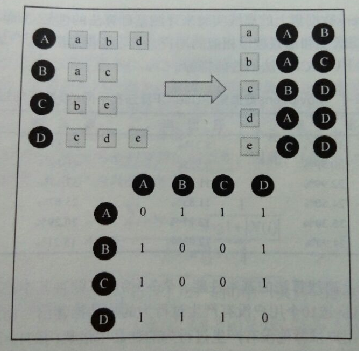
Where N(u) is the item set that user u has a positive feedback. Here is an example in book.
def UserSimilarity(train):
W = dict()
for u in train.keys():
for v in train.keys():
if u == v:
continue
W[u][v] = len(train[u] & train[v])
W[u][v] /= math.sqrt(len(train[u]) * len(train[v]) * 1.0)
return W
The time complexity of this code is O(|U| *|U|). Actually most of the time, there is no such item that both two users have positive feedback. That is, |N(u) ∩ N(v)| = 0 usually.
Hence, we can build the inverse table of items to users.
Assume user u and user v belong to the user list of K common items, then C[u][v] = K, where C is a sparse matrix.
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
# calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1
# calculate final similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
An improved algorithm User-IIF: Because there are some item popular that most user will have positive feedback, which can not reflect the similarity, User-IIF is put forward. In this method, it is considered that the unpopular items is better to reflect the similarity of two users. The improved formula of similarity is as follows:
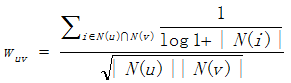
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
# calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1 / math.log(1 + len(users))
# calculate final similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
It is the second step now. In UserCF, it will return the items that the K most similar users favorite to the target user. The following formula will measure the degree of the target user’s interest in items.
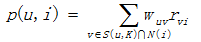
Where rvi means user v is interested in item i( rvi is always 1 ), and wuv means the similarity between user u and user v.
def Recommend(user, train, W):
rank = dict()
interacted_items = train[user]
for v, wuv in sorted(W[u].items, key = itemgetter(1), reverse=True)[0:K]:
for i, rvi in train[v].items:
if i in interacted_items:
# we should filter items user interacted before
continue
rank[i] += wuv * rvi
return rank
ItemCF
It is similar to UserCF, there are two steps mainly:
- Find the set of items which are similar to the target item.
- According to the similarity of items and the behavior of users, build commendation lists.
The first step is to calculate the similarity of items w.
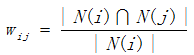
or
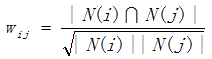
| Where | N(i) | means the number of users who is interested in item i. |
def ItemSimilarity(train):
# calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in items.keys():
N[i] += 1
for j in items.keys():
if i == j:
continue
C[i][j] += 1
# calculate final similarity matrix W
W = dict()
for i, related_items in C.items():
for j, cij in related_items.items():
W[i][j] = cij / math.sqrt(N[i] * N[j])
return W
Here is one improved algorithm because there are some popular items that the vast majority of people are interested in them. We know, in ItemCF, the similarity w is:
, then if j is popular item, |N(i) ∩ N(j)| ≈ |N(i)|. Hence, it’s put forward that w should be 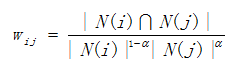 , where α∈[0.5, 1].
, where α∈[0.5, 1].
Of course, there is another improved algorithm like User-IIF for ItemCF, called ItemCF-IUF(Inverse User Frequence): Because there are some users are very active which is interested in most items. In IUF, it is considered that these active users contribute less similarity than inactive users.
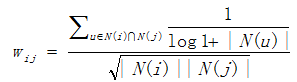
def ItemSimilarity(train):
# calculate co-rated users between items
C = dict()
N = dict()
for u, items in train.items():
for i in items.keys():
N[i] += 1
for j in items.keys():
if i == j:
continue
C[i][j] += 1 / math.log(1 + len(items) * 1.0)
# calculate final similarity matrix W
W = dict()
for i, related_items in C.items():
for j, cij in related_items.items():
W[i][j] = cij / math.sqrt(N[i] * N[j])
return W
ItemCF-Norm: The study found that it is better if normalize w, because sometimes the w differ greatly between different type.
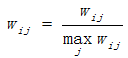
The second step is to find out K similar items and recommend to target user. Here is the formula to calculate target user’s interest in item j:
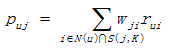
Where N(u) is the set of u’s favorite items, and S(j, K) is the set of the items which are K the most similar to item j.
def Recommendation(train, user_id, W, K):
rank = dict()
ru = train[user_id]
for i, pi in ru.items():
for j, wj in sorted(W[i].items(), key=itemgetter(1), reverse=True)[0:K]:
if j in ru:
continue
rank[j].weight += pi * wj
rank[j].reason[i] = pi * wj
return rank
Latent Factor Model
Ususally two popular item have high simularity, because most users have behavior with them. In such cases, the recommendation system could not be based on only users’ behavior. LFM is a method based on machine learning, which has better theory basis. In LFM, the formula to calculate the user u’s preference to item i is defined as:
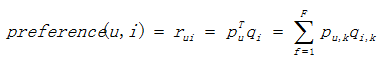
pu,k measures the relationship between user u’s interest and the kth implicit class, and qi,k measures the relationship between the kth implicit class and item i.
Then, how to get the pu,k and qi,k.
Here define a loss function C.
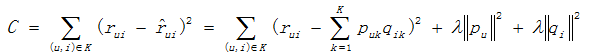
where 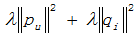 are the regular term and K is the total number of implicit class. To minimize C, find out the optimal pu,k and qi,k by using stochastic gradient descent method:
are the regular term and K is the total number of implicit class. To minimize C, find out the optimal pu,k and qi,k by using stochastic gradient descent method:
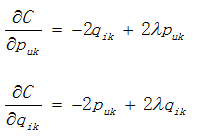 ->
-> 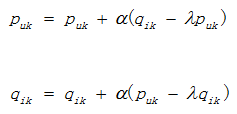
where α is learning rate, obtained by numerous experiments.
def RandomSelectNegativeSample(self, items):
# items: a set of items that the user has behavior with
ret = dict()
for i in items.keys():
ret[i] = 1
n = 0
# generate negative samples which are popular while the user doesn't have behavior
for i in range(0, len(items) * 3):
# len*3: to make sure the amount of positive and negative sample is similar
item = item_pool[random.randint(0, len(items_pools) - 1)]
# in item_pool, the times a item shown is proportional to its popularity
if item in ret:
continue
ret[item] = 0
n += 1
if n > len(items):
break
return ret
def LatentFactorModel(user_items, F, N, alpha, lambda):
# F: the number of implicit class
# alpha: the learning rate
# lambda: the parameter of regular term
[P, Q] = InitModel(user_items, F)
for step in range(0, N):
for user, items in user_items.items():
samples = RandSelectNegativeSamples(items)
for item, rui in samples.items():
eui = rui - Predict(user, item)
for f in range(0, F):
P[user][f] += alpha * (eui * Q[item][f] - lambda * P[user][f])
Q[item][f] += alpha * (eui * P[user][f] - lambda * Q[item][f])
alpha *= 0.9
def Recommend(user, P, Q):
rank = dict()
for f, puf in P[user].items():
for i, qfi in Q[f].items():
if i not rank:
rank[i] += puf * qfi
return rank
Random Walk on Graph
Graph-based model is important content of recommended system. Actually, always neighborhood-based model also called graph-based model.
Here bipartite graph G(V, E) is used to represent users’ behavior data, where V represents the vertexs of users and items, and E represents the edge between users and items.
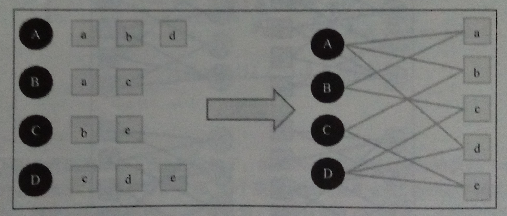
There is a graph algorithm called Personal Rank.
Suppose to give the user u personalized recommendation, then it can random walk start from the vertex corresponding to user u. According to the probability α to decide whether continue to walk or stopped to restart from the beginning vertex. If continue, select one vertex randomly that the current vertex connects to as the next vertex. After a number of random walk, the probability of each item vertex passed through will converge to a exact number.
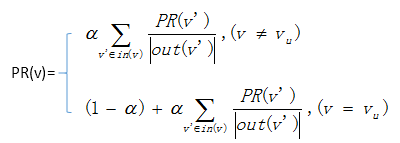
def PersonalRank(G, alpha, root):
rank = dict()
rank = {x:0 for x in G.keys()}
rank[root] = 1
for k in range(20):
tmp = {x:0 for x in G.keys()}
for i, ri in G.items():
for j, wij in ri.items():
if j not in tmp:
tmp[j] = 0
tmp[j] += alpha * rank[i] / (1.0 * len(ri))
if j == root:
tmp[j] += 1 - alpha
rank = tmp
return rank
This method has high time complexity, one of the solutions is theory of matrices.
Assume M is a matrix of PR, then 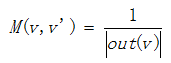 . So the formula above can be converted to
. So the formula above can be converted to 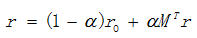 then
then 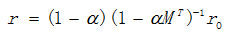 .
.